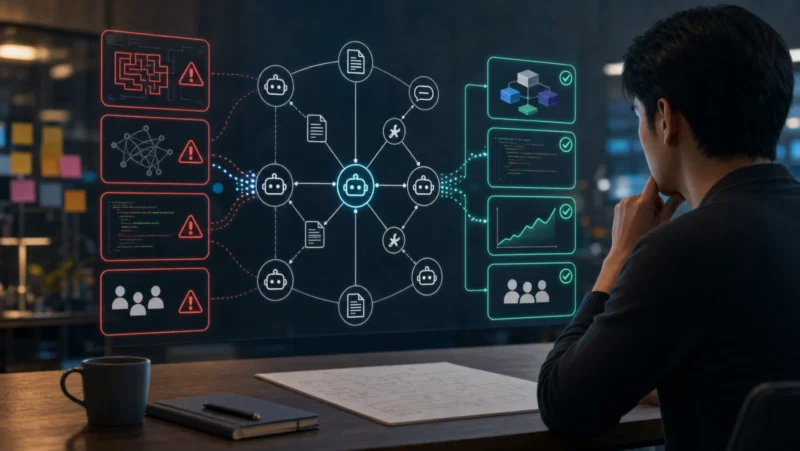


基于 Codex 等代码生成模型的多智能体(Multi-Agent)系统,正在将软件开发的核心从“手动编写代码”转变为“管理智能体工作流”。在实际的代理式开发(Agentic Workflow)中,系统通常由需求拆解、代码编写、测试审查等多个专属智能体协同工作。人类开发者的角色随之转变为系统架构师与最终决策者。这种模式能极大缩短产品从概念到原型的周期,但同时也对上下文状态管理、任务边界划分和自动化测试覆盖率提出了极其苛刻的要求。
代理式开发流程中最容易踩坑的环节是什么?
将代码编写权交给智能体网络后,最容易导致项目失控的往往不是模型本身的编码能力,而是工作流的设计缺陷。在实际工程落地中,以下几个环节是重灾区:
- 上下文丢失与幻觉累积:智能体在处理跨文件的大型重构时,极易遗忘初始约束条件。如果缺乏严格的状态管理,智能体会为了修复一个 Bug 而引入三个新 Bug。排查清单中必须包含“每次迭代前强制重置并注入核心上下文”的机制。
- 调试死循环(Infinite Debugging Loops):当测试智能体与编码智能体相互纠错时,可能会陷入无休止的循环。必须在工作流中设置明确的干预阈值(例如连续失败 3 次后强制交由人类接管),避免消耗大量 Token 且产出无效代码。
- 过度工程化(Over-engineering):智能体倾向于使用复杂的模式来解决简单问题。如果没有在提示词中明确限制技术栈和依赖库,最终可能会得到一个包含大量冗余抽象层的代码库。
哪些开发能力与基建会形成长期复利?
在代理式开发范式下,一次性的代码产出价值正在降低,而能够提升智能体运行效率的“基础设施”将成为团队的核心资产。以下三个方向的投入会产生显著的复利效应:
- 高覆盖率的自动化测试基建:智能体生成的代码需要明确的“验收标准”。测试用例越完善,智能体重构和迭代代码的安全网就越牢固。测试驱动开发(TDD)在多智能体工作流中不仅是规范,更是刚需。
- 代码库上下文映射(Context Mapping):构建针对本地代码库的高质量 RAG(检索增强生成)系统。当智能体能够精准检索到团队的历史架构决策、API 规范和私有组件库时,其输出的代码质量会呈指数级上升。
- 定制化工具与函数调用库:为智能体提供封装好的内部工具(如数据库查询、日志分析、部署脚本)。智能体调用的工具越丰富,其能独立完成的端到端任务就越复杂。
开发者如何将精力聚焦于高价值的架构判断?
当基础的增删改查和单元测试交由 Codex 及智能体完成,人类开发者的注意力必须向上层转移,专注于 AI 难以处理的全局性与战略性问题:
- 定义系统边界与接口契约:AI 擅长实现具体的函数,但不擅长划分微服务边界。开发者需要花更多时间设计清晰的 API 契约和数据流向,让智能体在既定的框架内“填空”。
- 安全性审查与边界异常处理:智能体往往关注“主流程”的实现,容易忽略并发竞争、内存泄漏或恶意输入等边缘场景。人类的代码审查应从语法细节转向业务逻辑漏洞和安全合规性。
- 技术栈选型与成本评估:引入新框架或第三方服务时,需要人类结合团队现状、维护成本和商业目标进行综合判断,这是目前任何智能体都无法替代的商业级决策。
我之前写过一篇关于Codex的文章:《Codex最新解读:rust v0.141.0》,如果你担心踩坑或正在排查类似问题,顺手一起看会更有帮助。
常见问题
Q: 多智能体工作流适合所有类型的软件项目吗?
A: 更适合从零到一的原型开发、内部工具构建以及具有高测试覆盖率的成熟项目。对于缺乏文档、高度耦合的老旧遗留系统(Legacy Code),智能体极易因上下文混乱而产生破坏性修改。
Q: 代理式开发和日常使用的 Copilot 插件有什么区别?
A: Copilot 属于“副驾驶”模式,依赖人类在编辑器中实时引导和补全;而代理式开发是“自动驾驶”模式,智能体可以自主读取 Issue、规划步骤、修改多个文件并运行测试,人类仅在关键节点进行审批。
Q: 如何防止智能体在重构时破坏原有业务逻辑?
A: 必须建立“无测试不重构”的硬性规则。在让智能体介入核心逻辑前,先要求其生成针对该模块的详尽端到端测试,确保测试通过后,再授权其进行代码修改。



暂无评论内容